
ChatGPT, Gemini, DeepSeek... New AI models seem to emerge every month, yet most people still default to GPT-4o.
What few realise is that, despite its popularity, GPT-4o exhibits less variation in its outputs compared to other models. This lack of diversity in output is more than a technical quirk, it’s a creative warning sign.
This concern partly inspired an independent, industry-led initiative, backed by AI platform Springboards, to create the first comprehensive benchmark evaluating large language models’ (LLMs) creative instincts in advertising.
As AI tools become integral to strategists’ and creatives’ workflows, this benchmark, CreativityBenchmark.ai, aims to fill a critical gap by assessing AI models across three creative dimensions: creative problem-solving, variance, and insight and idea inspiration.
Existing AI benchmarks focus on logic, accuracy, and comprehension, often designed to to evaluate models on tasks related to finance, law, or coding, not to generate ideas, solve creative briefs, or tell compelling stories. Advertising thrives on originality, insight, and impact, not just right answers. This benchmark is the first tailored to the creative instincts valued by agencies and brands, helping creative professionals understand which models truly support their work.

Behind the scenes, a technical and research team, including PhDs in machine learning, AI engineers, and former Google researchers, developed a system blending data analysis with human taste to identify which models excel in different types of creative thinking.
Globally, participants will judge model outputs through a 'Tinder for Ideas' experience, gaining personal insights into their creative preferences and discovering which LLMs best match their style.
Campaign spoke with Pip Bingemann, CEO and co-founder of AI platform Springboards, to explore the benchmark’s goals and why the industry urgently needs it now.
1. What is the main goal of establishing a creativity benchmark for LLMs in advertising and why now?
LLMs have been benchmarked for logic, not imagination. We’ve been told hallucinations are bad, but they’re not bad, they’re different. And in creativity we often want hallucinations. We want inspiration from the outliers, not the averages.
So the main reason for this benchmark is to challenge the current benchmarks these models are trained on. Most existing ones focus on science, maths, law, and general knowledge, where having the ‘right’ answer matters. But when models compete to be right, they start to converge. Variance in outputs goes down.
And when people are using these tools for creative inspiration, that sameness becomes a problem. How can we expect original ideas if everyone’s getting similar answers?
The current LLMs just aren’t built for what the creative industry actually needs. This benchmark is a start, it helps raise awareness of the importance of inspiration and variance in LLMs, not just accuracy.
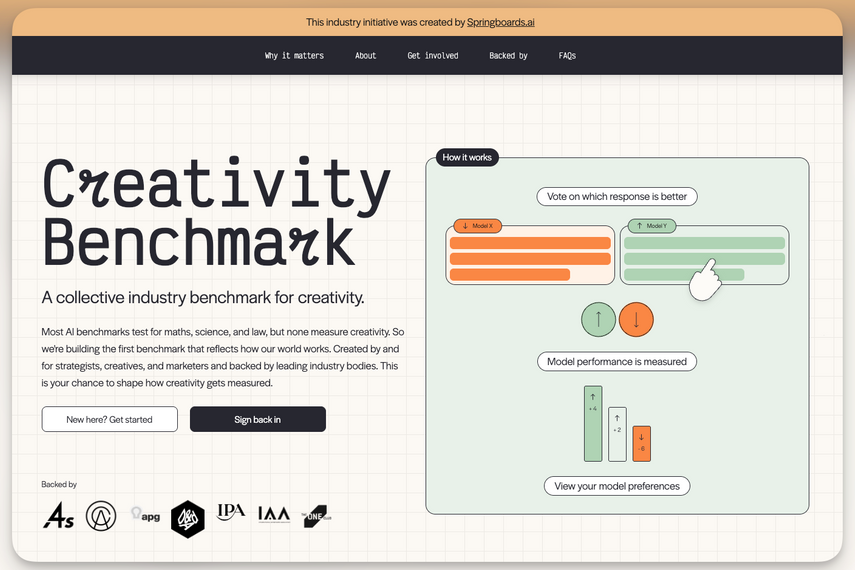
2. How will it work? And how does the benchmark define and measure “creativity” in LLMs, given its subjective and cultural nature?
We treat creativity as a mix of originality, usefulness, and variance of inspiration. There are three main tests. One that looks at the variance of the models, one that looks at the creative problem solving ability and one the looks at the subjectivity of the models outputs to inspire creativity.
The subjectivity parts is done via a 'tinder for ides' experience on Creativitybenchmark.ai. People are given either an insight, idea or wild idea for a random brand and asked to pick what they prefer and after doing 15 tests they will get their personal model preference and also contribute to the broader study so we can then look at the subjectivity of these models by different regions, job functions etc.
The two other parts are done by sending over 50k prompts to the models to measure the 'distance' within the embeddings spaces the models send people to and how they answer traditional creative test type questions inspired by the Torrance test.
3. Given that the benchmark seeks to determine which models are "best at generating new and original creative ideas," how do you address concerns that this pursuit might lead to "handing over" core creative ideation to machines?
The objective of the study is to not crown a winner but to highlight that variation in outputs, subjectivity and human inspiration is vital. At the moment, the vast majority of people default to GPT-4o, but what most don’t know is that, while it is an amazing product, it actually has worse variance than other models. This is a major concern because if the most popular model starts giving everyone the same answers, then the world starts to turn grey very quickly. Diversity of models, of thought, of randomness, variation and hallucinations are all important so that it helps creativity stay human and not just push us all into the same place.
4. What ethical considerations arise if certain LLMs dominate creative output, and how will human accountability be ensured?
With all benchmarks it’s not a one and done thing, it’s ongoing. Benchmarks drive model development, and if we don’t create standards for creativity, we’ll keep getting models that aren’t built for it. Models are just raw material. It’s the tools, and the hands that wield them, that shape the creative outcomes. The ethical responsibility lies with everyone, the people building and deploying the tools, the leaders of brands, agencies, and people who choose how they’re used.
5. How will the benchmark address copyright and IP issues, given many LLMs are trained on or generate work from existing creative content?
This benchmark doesn’t attempt to solve IP or copyright issues. That’s a legal and technical challenge far beyond its scope. But what it can highlight is when models might be recycling thoughtlessly. It’s a starting point, not a solution, and we need broader frameworks alongside it.
The creativity benchmark is currently inviting strategists, creatives, and marketers to help evaluate AI-generated outputs by choosing which short insights they prefer. Participation is open to all industry professionals and takes only a few minutes. This collective input aims to ensure that human creativity remains central, with none of the evaluated outputs used for training AI models. Find out more here.
.jpg&h=334&w=500&q=100&v=20250320&c=1)



.png&h=334&w=500&q=100&v=20250320&c=1)



.png&h=334&w=500&q=100&v=20250320&c=1)

.jpg&h=268&w=401&q=100&v=20250320&c=1)
.jpg&h=268&w=401&q=100&v=20250320&c=1)




.png&h=268&w=401&q=100&v=20250320&c=1)
